
Intro
Before even starting: I’m not trying to create a new language, at all. This is just for fun.
In the past few days, I have been writing a Tree-Walk interpreter in Golang, following almost the same Java implementation of the Lox language (described in the Crafting Interpreters book).
I changed really tiny things in the syntax, and in the grammar of the language, so I decided to name it differently: Vetryx ;D
I also skipped a few things (like adding support to classes).
Be advised that I might have introduced some bugs in the process of making such changes… I tried to add as much unit tests as possible (considering this is something I’ve done in my free time and again, just for fun 😄), but I could have missed something anyway…
Links
- Tiny documentation about the Vetryx language here.
- A playground (quick and dirty) to try the interpreter in a simple way.
Resources
- The amazing book: Crafting Interpreters, written by Robert Nystrom. I really suggest you to read it!
Motivation
Sometimes I forget how much I enjoy coding stuff just for fun.
For me it have always been fun to learn new languages. I’ve been coding in Go for quite a while now (years…), and I absolutely love it. But I also love Python, and PHP, and C, and even VB6, and so many more…
Going back to my beginnings, I actually started coding in classic ASP (yeah, I’m not even talking about .NET), and tho I would not use it for any new project nowadays, I enjoyed A LOT the time I spent with that language as well..
I’m only 28 years old at the time of writing this (and around 18 when I started with ASP). So no, I’m not a dinosaur 🦖 😀
But back to the question, why did I decide to spend some days coding this interpreter?
I still remember my times in college, learning data structures and algorithms in depth. Studying how OS works in the low level. Understanding semaphores theory. Using graph algorithms to find the shortest path between two areas of the city. Getting hands on with a new Arduino, and designing some robot to do something I could actually touch with my own hands. Writing AI programs using Prolog. And so many more things… Those times were so exciting.
One of the topics I spent lot of time learning about at that time, was compilers… It’s been a while since I wanted to dive deeper again into this exciting topic to refresh my knowledge about it (and learn new things), but I’ve been postponing it for one thing or the other… So I decided now is the time to get back to it.
Programming languages are really cool. But what’s even cooler to me, is to understand what lies underneath. How do they actually get converted to machine code? 1s and 0s? To electricity?
This implementation, is not actually compiling to machine code, but instead it uses Go to interpret Vetryx, by scanning the code, parsing it into an abstract syntax tree (also known as AST), and then interpreting it on the run.
Important stuff about the language:
- It is dynamically typed
- Imperative
- Interpreted
Quick Theory
Let’s mention the essential things about an interpreter.
First what is an interpreter?
Your code doesn’t run directly in the machine in the way you write it in your favorite language (but I’m pretty sure you know that already). A computer in the low level doesn’t know anything about words, or “whiles”, or whatever.
In short: An interpreter is a program that interprets a high-level language code, during runtime, executing the instructions line by line.
The main difference between an interpreter and a compiler, is that the last one compiles the whole code in advance to some lower level code (including native machine code) without actually running it.
But is that all?
Not really. There are things in the middle as well. For example, some languages like Java, are compiled first into bytecode, and then interpreted by a VM (for the case of Java: the famous JVM). So this is more of a mix.
There is more stuff out there as well, but I will not extend much here. Just google a bit about the topic, and you will find out..
Compiled languages examples: Golang, C, etc..
Interpreted languages examples: Python, PHP, etc..
Usually compiled languages are much faster than interpreted ones, because they don’t have an extra overhead. They are directly compiled to machine code. So they get executed much faster.
Just bear in mind that down there, in the lowest possible level everything is just a bunch of ones and zeroes. Just electricity. Low voltage, high voltage.
At the moment of executing the code, the more layers the machine have to cross between the high level code, and those 1s and 0s, the more time it will take to execute it. So, if the code is already compiled to “machine code” before execution, naturally things will go much faster.
If you like the hardware part, I also recommend the following interesting book (which is not about compilers or interpreters, but about circuits, 1s, 0s): Code.
To avoid making this post huge, more info about interpreters here.
Also this repo is really interesting ✨.
Last but not least, I recommend again the book I’ve been reading: Crafting Interpreters.
Really… Just read it, you will love it! And no, I’m not Bob’s friend, just another reader 😂
The main components
To keep this post short, but also give you an idea of the structure of the interpreter before you get confused with the code, I will (extremely briefly) explain the main components of it:
Scanner (a.k.a: lexer)
It converts the raw source code, into a list of tokens. Example:
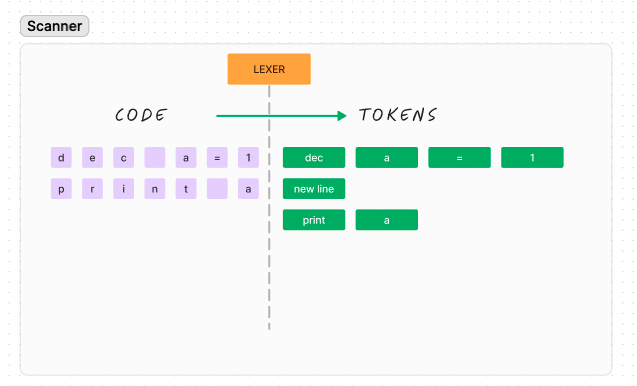
Fragment of its code:
// scanSingleChar handle the scanning of single chars (simple logic).
func (s *Scanner) scanSingleChar(char rune) {
switch char {
case '{':
s.addToken(token.LeftBrace, nil)
case '}':
s.addToken(token.RightBrace, nil)
case '(':
s.addToken(token.LeftParentheses, nil)
case ')':
s.addToken(token.RightParentheses, nil)
case ',':
s.addToken(token.Comma, nil)
case '+':
s.addToken(token.Plus, nil)
case '-':
s.addToken(token.Minus, nil)
case '*':
s.addToken(token.Star, nil)
case '/':
s.addToken(token.Slash, nil)
case '%':
s.addToken(token.Modulus, nil)
case '!':
s.addToken(token.Bang, nil)
case '#':
// comments special handling
for s.peek() != '\n' && !s.isEnd() {
s.increment() // skip everything until the comment ends
}
}
}Piece of code from the repo 🙂
Parser
It converts the tokens (output of the previous step) into the AST (abstract syntax tree). This is what’s called “parsing”. This part is dense, so try to understand it step by step, with a bunch of coffee ☕️

Image from Wikipedia. Link: https://en.wikipedia.org/wiki/Abstract_syntax_tree.
Fragment of its code:
// variable parses a variable declaration.
func (p *Parser) variable() (ast.Statement, error) {
name, err := p.consume(token.Identifier)
if err != nil {
return nil, fmt.Errorf("expected a valid variable name: %w", err)
}
var variableValue ast.Expression
if p.is(token.Equal) {
p.increment() // skip the equal
variableValue, err = p.expression()
if err != nil {
return nil, err
}
}
_, err = p.consume(token.NewLine)
if err != nil {
return nil, fmt.Errorf("expected a new line or EOF after the variable declaration: %w", err)
}
return ast.NewVariableStatement(name, variableValue), nil
}Piece of code from the repo 🙂
Interpreter
This is the most fun part (at least for me). We basically traverse the AST tree constructed in the previous step, and we “interpret” each node, using Golang…
Fragment of its code:
func (i *Interpreter) VisitWhileStatement(statement *ast.WhileStatement) error {
env := i.env
for {
evalCondition, err := statement.Condition.Accept(i)
if err != nil {
return err
}
if !corerule.IsTrue(evalCondition) {
break
}
err = statement.Body.Accept(i)
if err != nil {
i.env = env // This is necessary, so the environment is properly reseted. Same as we do in "executeBlock()".
if errors.Is(err, Break{}) {
break
}
if errors.Is(err, Continue{}) {
continue
}
// If is not break or continue, we return the real error
return err
}
}
return nil
}Piece of code from the repo 🙂
Some other stuff
There are other layers you will find in the code, such as:
Resolver: It resolves the scoping of declarations (eg: variables, functions, etc…).
The implementation of the resolver is based on a stack.
Environment: We need some place to store our variables with its values, the functions, etc… For that, we use the “environment” layer. It’s implemented as a hash table. Important: An environment can also have a parent environment (resulting in a recursive structure).
Native functions: These are some functions provided by “our language” out of the box. For example: clock, sleep, min, max, etc…
The AST itself: It is implemented using the visitor pattern (as explained in the book).
The interpreter in action
As mentioned at the beginning of the post, I have built a really simple playground with Next.js, which you can try out here.
What it actually does in the background, is calling an API exposed by govetryx, that calls the interpreter and executes the code. Then it just prints the output.
Example:
fn fibonacci(n) {
a := 0
b := 1
if n < 0 {
print "invalid input"
}
if n == 0 {
return a
}
if n == 1 {
return b
}
i := 2
while i < n+1 {
c := a + b
a = b
b = c
i = i + 1
}
return b
}
print fibonacci(10)Output:
# Output:
55What now?
If you are interested on this topic, just get your hands dirty, and try to understand each piece of the code 🙂 IMO it’s the best way to learn!
Also, I know I said it many times, but read the Crafting Interpreters book!!!
I also plan to work on a more complex and way faster interpreter (that compiles to bytecode first, and then executes it with a VM coded in C), when I find some free time to do so… That’s the second part of Bob’s book.
Acknowledgment
I know, I’ve been mentioning Crafting Interpreters book during the whole post, and its awesome author: Bob Nystrom.
I wanted to say it one more time: what a great fascinating book!!!!
It’s so well written, and the implementation is so clean and clear to understand.
All credit and kudos to Bob Nystrom. Thanks a lot for writing that piece of art and sharing the code with everyone.
Last
But not least 🙂
I hope you enjoyed this post, and I hope I transmitted you some motivation to get your hands dirty with this topic.
Thanks for reading!
Leave a Reply